Privacy Policy
Projects
News
Company
Careers
Chainer
Tag
Category
Year
Keyword
News Release
2020.07.30
PyTorch向け深層強化学習ライブラリ PFRLをオープンソース公開
2020.05.12
PyTorchコミュニティとの連携を強化
2019.12.05
Preferred Networks、深層学習の研究開発基盤をPyTorchに移行
2019.10.07
アフレルとPreferred Networks、共同開発によるプログラミング教材 「実践!Chainerとロボットで学ぶディープラーニング」を公開
2019.05.16
オープンソースの深層学習フレームワークChainerおよび 汎用配列計算ライブラリCuPyの最新版v6をリリース
2019.04.10
深層学習の初心者向けに、日本語の オンライン学習資料「ディープラーニング入門:Chainer チュートリアル」を無料公開
2019.02.01
第37回 日経優秀製品・サービス賞 日本経済新聞賞 (2018年度最優秀賞)
2018.12.03
N次元配列の自動微分をC++で実装したChainerXをリリース。Chainer v6(β版)に統合し、計算パフォーマンスを向上
2018.10.25
オープンソースの深層学習フレームワークChainer および 汎用配列計算ライブラリCuPy の最新版となるv5をリリース
Topic
2018.05.17
ODSC East 2018で、Chainerが Open Source Data Science Project賞を受賞
2018.04.17
オープンソースの深層学習フレームワークChainer および 汎用配列計算ライブラリCuPy の最新版となるv4をリリース
2017.11.10
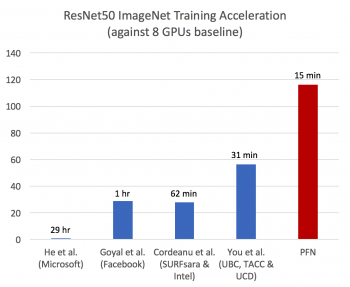
Preferred Networks、深層学習の学習速度において世界最速を実現
お問い合わせはこちらまで。