NVIDIA GPUなどの最新技術を採用した プライベート・スーパーコンピュータ MN-2 を自社構築し、7月に稼働
2019.03.18
MN-1、MN-1b、MN-2合計で約200※1ペタフロップス※2の計算資源を保有
株式会社 Preferred Networks(本社:東京都千代田区、代表取締役社長:西川徹、プリファードネットワークス、以下、PFN)は、プライベート・スーパーコンピュータ MN-2(エム・エヌ・ツー)を自社構築し、2019年7月に稼働します。
MN-2は、NVIDIA(R) V100 Tensor コア GPUを搭載した最新のマルチノード型GPGPU※3計算基盤で、すでにPFNが保有するプライベート・スーパーコンピュータMN-1(2017年9月稼働)、MN-1b(2018年7月稼働)と合算して、PFNは合計約200 ペタフロップスの計算資源を保有することになります。またMN-2の構築に並行して、PFNが独自開発するディープラーニング・プロセッサー MN-Core(TM) によるプライベート・スーパーコンピュータ MN-3を2020 年春に稼働予定です。
PFNは継続的に計算資源に投資することで、深層学習の研究開発および関連技術の実用化を加速し、世界的な開発競争における優位性を確保していきます。

MN-2の完成イメージ
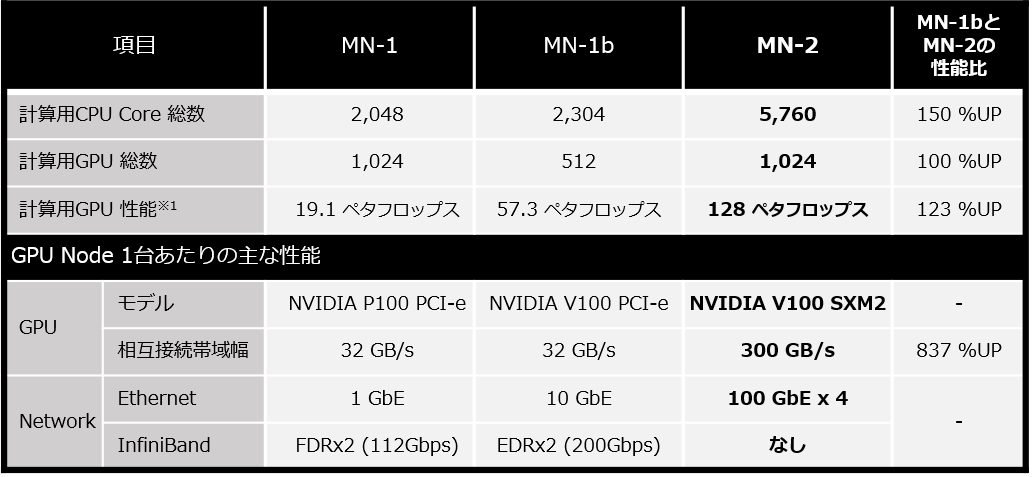
PFNの次期プライベート・スーパーコンピュータ MN-2(エム・エヌ・ツー) の概要
PFNは、2019年7月より、最新CPUを5,760CoreとNVIDIA V100 Tensor コアGPUを1,024基搭載した MN-2を稼働します。MN-2は、国立研究開発法人海洋研究開発機構 横浜研究所 シミュレータ棟内に構築され、2020年稼働予定のMN-3と同一サイト内で連携稼動し、さらに、現在稼働中のMN-1およびMN-1bとも閉域網で接続されます。MN-2の理論上のピーク性能は、深層学習で利用される混合精度浮動小数点演算において約128ペタフロップスであり、MN-2のみでMN-1bの2倍以上のピーク性能となります。
MN-2のGPUノード間インターコネクトは、RoCEv2※4の採用に併せて1ノードあたり100ギガビットイーサネットを4本搭載し、PFN独自のチューニングを行うことで、マルチノードの高速処理を実現します。同時に総容量10PBを超えるソフトウェア・デファインド・ストレージ※5を独自に構築して機械学習時のデータアクセスを最適化することで、学習の高速化を図ります。
PFNはこのMN-2の上でオープンソースの深層学習フレームワークChainer(TM)(チェイナー)を活用し、大量の計算資源を必要とするパーソナルロボット、交通システム、製造業、バイオ・ヘルスケア、スポーツ、クリエイティブ分野での研究開発をより一層加速させます。
株式会社Preferred Networks 執行役員 システム担当VP 秋葉 拓哉のコメント
我々はこれまでも、最先端のNVIDIA GPUを用いた大規模データセンターを活用し、ディープラーニングとその応用に関する研究開発を行ってきました。高い計算力はディープラーニングの研究開発を支える大きな柱の1つです。今回NVIDIA V100を1,024基搭載したMN-2を構築することで、研究開発をさらに加速することができると確信しています。
エヌビディア合同会社 日本代表 兼 米国本社副社長 大崎 真孝 様のコメント
Preferred Networksが、現在運用中のMN-1およびMN-1bに加え、最先端のデータセンター向けGPUであるNVIDIA V100 を採用したMN-2を構築されることを歓迎いたします。超高速なGPU間通信を実現するNVLINKを搭載した、NVIDIAのフラグシップGPUにより、ディープラーニングおよび関連技術の研究開発がより一層加速され、世界をリードする成果が生まれることを心より期待しております。
※1:MN-1は半精度浮動小数点演算能力、MN-1bおよびMN-2は混合精度浮動小数点演算能力。混合精度浮動小数点演算は、複数の精度の浮動小数点演算を組み合わせて利用する方式のこと。
※2:コンピュータの処理能力を表す単位の一つ。peta (ペタ) は1,000兆(10の15乗)、FLOPS (フロップス) は1秒間に行える浮動小数点演算の回数を表すので、1ペタフロップスは毎秒1,000兆回の浮動小数点演算を行えることを意味する。
※3:General-purpose computing on GPU(GPUによる汎用計算)
※4:RDMA over Converged Ethernet。遠隔ノード間での直接メモリアクセス (RDMA) を実現するネットワークプロトコルの一つで、イーサネット上で低遅延・高スループットを実現する方式
※5:分散するデータストレージの使用効率を高めるためソフトウェアにより一元管理されたストレージシステム
*MN-Core(TM)、Chainer(TM)は、株式会社Preferred Networksの日本国およびその他の国における商標または登録商標です。


