Preferred Networks、深層学習の学習速度において世界最速を実現
2017.11.10
大規模な並列コンピュータを活用し、分散学習パッケージChainerMNでImageNetの学習を15分で完了
株式会社Preferred Networks(本社:東京都千代田区、代表取締役社長:西川徹、プリファードネットワークス、以下、PFN)は、大規模な並列コンピュータ「MN-1※1」を活用し、深層学習(ディープラーニング)の学習速度において世界最速を実現しました。
深層学習モデルの精度を向上させるため、学習データのサイズやモデルのパラメータ数が増加し、それにともなって計算時間も増大しています。1回の学習に数週間かかることも稀ではありません。複数のコンピュータを連携させて学習を高速化することは、新たなアイディアの試行錯誤や検証に要する時間を圧縮し、素早く研究成果をあげていくために非常に重要です。
一方で、複数のコンピュータを使った並列分散学習においては、通常、GPU数を増やすほどバッチサイズが大きくなることに加え、GPU間の通信にオーバーヘッドが存在することで、得られるモデルの精度や学習スピードが徐々に下がっていくことが知られています。
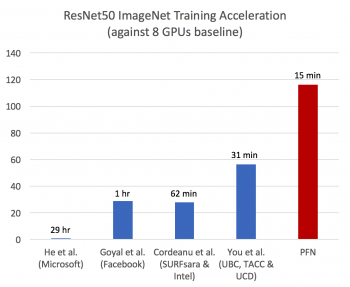
今回、これらの課題を克服するため、学習アルゴリズムと並列化性能の改善をおこない、1,024GPUで構成される民間企業で国内最大級の並列コンピュータMN-1と、分散学習パッケージ ChainerMN※2(チェイナー・エムエヌ)を用いて学習を行いました。
その結果、ImageNet※3の画像分類データセットを利用したResNet-50※4の学習を15分で完了し、同様の研究報告※5としてこれまで最速とされていた学習時間を大幅に短縮しました。
今回の研究成果は「Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes」というタイトルで、次のURLで公開しました。
(imagenet_in_15min.pdf)
PFNはこの研究成果をいかして、大規模な深層学習を必要とする交通システム、製造業、バイオ・ヘルスケア分野での研究開発をより一層加速させていきます。
■ オープンソースの深層学習フレームワークChainerについて
PFNが中心となって開発・提供するChainerは、Pythonベースのディープラーニング向けフレームワークであり、“Define-by-Run”の手法を通じて簡単かつ直感的に複雑なニューラルネットワークを設計できる高い柔軟性とパフォーマンスを兼ね備えています。2015年6月にオープンソース化され、最も普及しているディープラーニング向けフレームワークの1つとして、学術機関だけでなく、ディープラーニングがもたらすメリットを現実世界のアプリケーションや研究に活用するための柔軟なフレームワークを求める産業界の多くのユーザーに支持されています。
Chainerは、最新の深層学習研究の成果を迅速に取り入れ、ChainerMN(分散深層学習)/ChainerRL(強化学習)/ChainerCV(コンピュータ・ビジョン)などの追加パッケージ開発、Chainer開発パートナー企業のサポートなどを通して、各分野の研究者や実務者の最先端の研究・開発活動を支援していくことを目指しています。(http://chainer.org/)
■ 株式会社Preferred Networksについて
IoTにフォーカスした深層学習技術のビジネス活用を目的に、2014年3月に創業。デバイスが生み出す膨大なデータを、ネットワークのエッジで分散協調的に処理する「エッジヘビーコンピューティング」を提唱し、交通システム、製造業、バイオ・ヘルスケアの3つの重点事業領域において、トヨタ自動車株式会社、ファナック株式会社、国立がん研究センターなどの世界をリードする組織と協業し、イノベーションの実現を目指しています。(https://www.preferred.jp/ja/)
*Chainer(R) は、株式会社Preferred Networksの日本国およびその他の国における商標または登録商標です。
※1 NVIDIA(R) Tesla(R) P100を1,024基搭載。民間企業のプライベートな計算環境で国内最大級 https://www.preferred.jp/ja/news/pr20170920
※2 オープンソースの深層学習フレームワークChainer(チェイナー) にマルチノードでの分散学習機能を追加するパッケージ
※3 一般に広く使われている画像分類データセット
※4 画像認識の分野で多用されるネットワーク
※5 Intel(R) Xeon(R) Platinum 8160を1,600台使用して31分で学習完了(Y. You et al. ImageNet Training in Minutes. CoRR,abs/1709.05011, 2017)
