オープンソースの深層学習フレームワークChainerに、 マルチノードでの分散学習機能を追加するChainerMN(β版)をリリース
2017.05.09
本日、株式会社Preferred Networks(本社:東京都千代田区、代表取締役社長:西川徹、プリファードネットワークス、以下、PFN)は、オープンソースの深層学習フレームワークChainer(チェイナー)に、複数GPUの連携による分散学習機能を追加することで、学習速度を高速化させた追加パッケージ ChainerMN(チェイナー・エムエヌ、「MN」は「Multi Node」の略、https://github.com/pfnet/chainermn)のβ版をリリースしました。
GPUの性能は継続的に向上していますが、より大きなデータを活用し、より精度の高い学習モデルを実現するために、深層学習で使われるモデルのパラメータ数や計算量も増大しています。そのため現在でも、Chainer を含む一般的なフレームワークを用いた標準的な学習では 1週間以上かかるようなユースケースが少なくありませんでした。
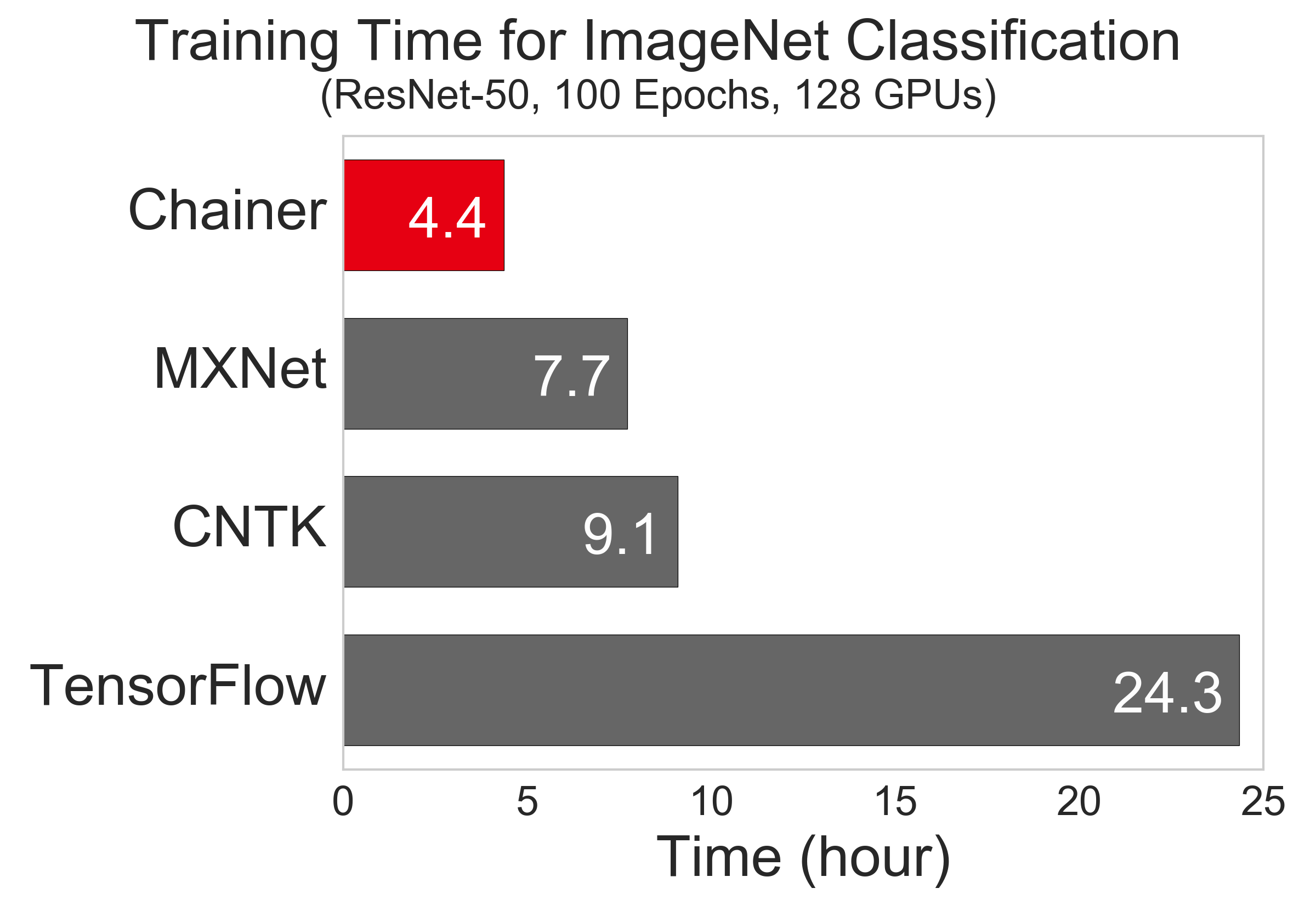
PFNでは、より大規模なデータを扱ったり、試行錯誤のイテレーションを効率化するために、複数のGPUを連携させ、マルチノードでの分散学習機能を実装したChainerMNを開発しました。実験では「32ノード/128GPU」を動作させ、「1ノード/1GPU」で約20日を要する学習を、4.4時間で終わらせることに成功しています。
ChainerMNと他のフレームワークとの性能比較実験
https://research.preferred.jp/2017/02/chainermn-benchmark-results/
128 GPU を用い、速度のために精度を犠牲にしない実用的な同一設定下で、各フレームワークが学習完了に要する時間を比較した実験では、ChainerMN が最も高速という結果になりました。
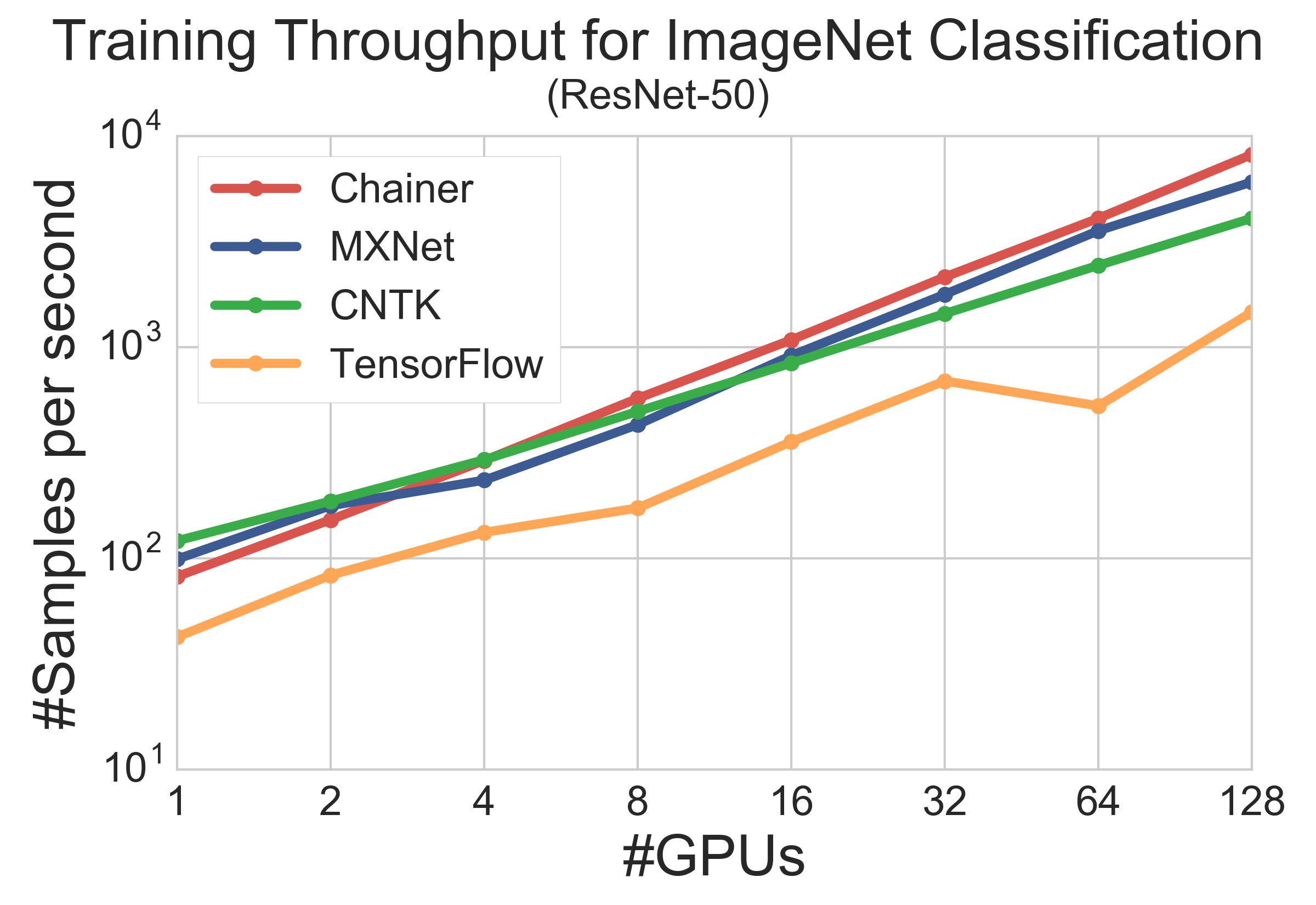
また、GPU 数を変えた時の各フレームワークのスループットでは、1GPU の時にはC++ で記述されたMXNet, CNTK のほうがPython で記述されているChainerMN よりも高速であるものの、128 GPU では、ノード内・ノード間の両方で高速な通信を実現した ChainerMN が最も高速であり、スケーラビリティがあるという結果になりました。
ChainerMNは高速でスケーラブルなだけでなく、Chainerのユーザーであれば既存の学習コードから数行の変更をするだけで簡単にChainerMNを利用可能です。
ChainerMNは既に社内の複数のプロジェクトで利用されており、自然言語処理分野や強化学習分野での試用も始まっています。
オープンソースの深層学習フレームワークChainerについて
PFNが開発・提供するChainerは、Pythonベースのディープラーニング向けフレームワークとして、“Define-by-Run”の手法を通じてユーザーが簡単かつ直感的に複雑なニューラルネットワークを設計するための高い柔軟性とパフォーマンスを兼ね備えています。2015年6月にオープンソース化されたChainerは、最も普及しているディープラーニング向けフレームワークの1つとして、学術機関だけでなく、ディープラーニングがもたらすメリットを現実世界のアプリケーションや研究に活用するための柔軟なフレームワークを求める産業界の多くのユーザーに支持されています。(http://chainer.org/)
株式会社Preferred Networksについて
IoTにフォーカスした深層学習技術のビジネス活用を目的に、2014年3月に創業。デバイスが生み出す膨大なデータを、ネットワークのエッジで分散協調的に処理する「エッジヘビーコンピューティング」を提唱し、交通システム、製造業、バイオ・ヘルスケアの3つの重点事業領域において、イノベーションの実現を目指しています。
最先端の深層学習技術を提供するDeep Intelligence in-Motion(DIMo、ダイモ)プラットフォームをベースとしたソリューションの開発・提供をはじめ、トヨタ自動車株式会社、ファナック株式会社、国立がん研究センターなどの世界をリードする組織と協業し、先進的な取り組みを推進しています。(https://www.preferred.jp/ja/)
*Chainer、DIMoは、株式会社Preferred Networksの日本国およびその他の国における商標または登録商標です。
