Privacy Policy
Projects
News
Company
Careers
2019
Category
Year
Keyword
Event
2019.12.19
フーモア、Preferred Networks、エムツー、コミケ97に共同出展
News Release
2019.12.17
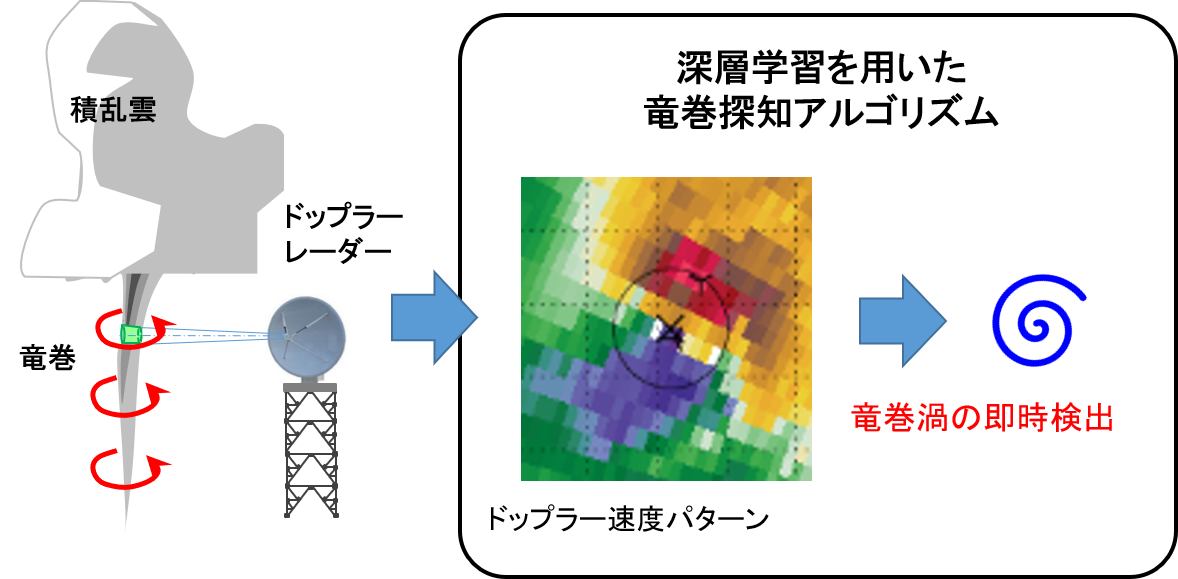
気象研究所と夏季の竜巻探知手法の開発契約を締結
2019.12.05
Preferred Networks、深層学習の研究開発基盤をPyTorchに移行
2019.11.20
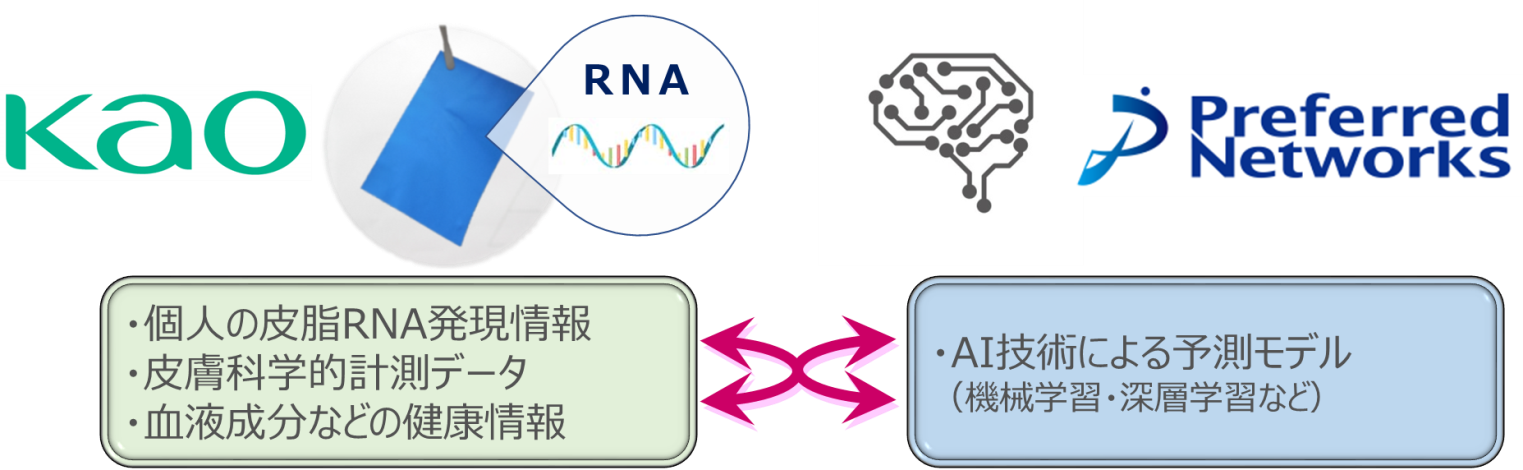
花王とPreferred Networks、皮脂RNAモニタリング技術の実用化に向けて協働プロジェクト開始
Topic
2019.11.19
PFNのResearch & Development サイトを新規公開しました
2019.11.15
ピクシブとPreferred Networksがイラスト自動着色分野で協業開始
2019.10.07
アフレルとPreferred Networks、共同開発によるプログラミング教材 「実践!Chainerとロボットで学ぶディープラーニング」を公開
2019.09.26
深層学習の実践的な学習を目的とした高等教育向け教材を山梨大学と共同開発
2019.08.16
2019年8月16日にCorporateサイトをリニューアルしました。
2019.08.07
トヨタ自動車とPreferred Networks、市場のニーズに応えるサービスロボットの共同開発を開始
2019.06.25
JXTGホールディングスから約10億円の資金調達を実施
2019.05.24
第5回 日本ベンチャー大賞 内閣総理大臣賞 を受賞
お問い合わせはこちらまで。