Privacy Policy
Projects
News
Company
Careers
ChainerMN
Tag
Category
Year
Keyword
News Release
2017.11.10
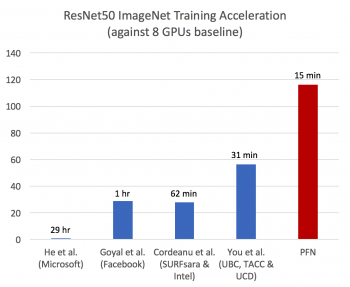
Preferred Networks achieved the world’s fastest training time in deep learning, completed training on ImageNet in 15 minutes,using the distributed learning package ChainerMN and a large-scale parallel computer
2017.09.20
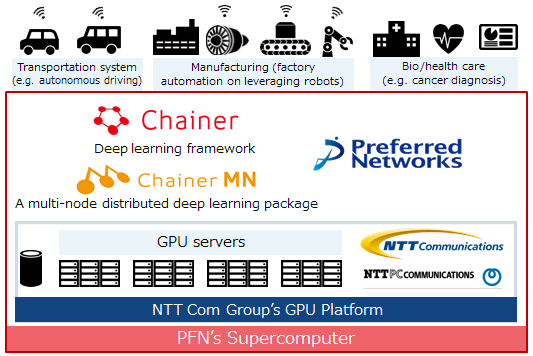
Preferred Networks Launches one of Japan’s Most Powerful Private Sector Supercomputers
2017.09.01
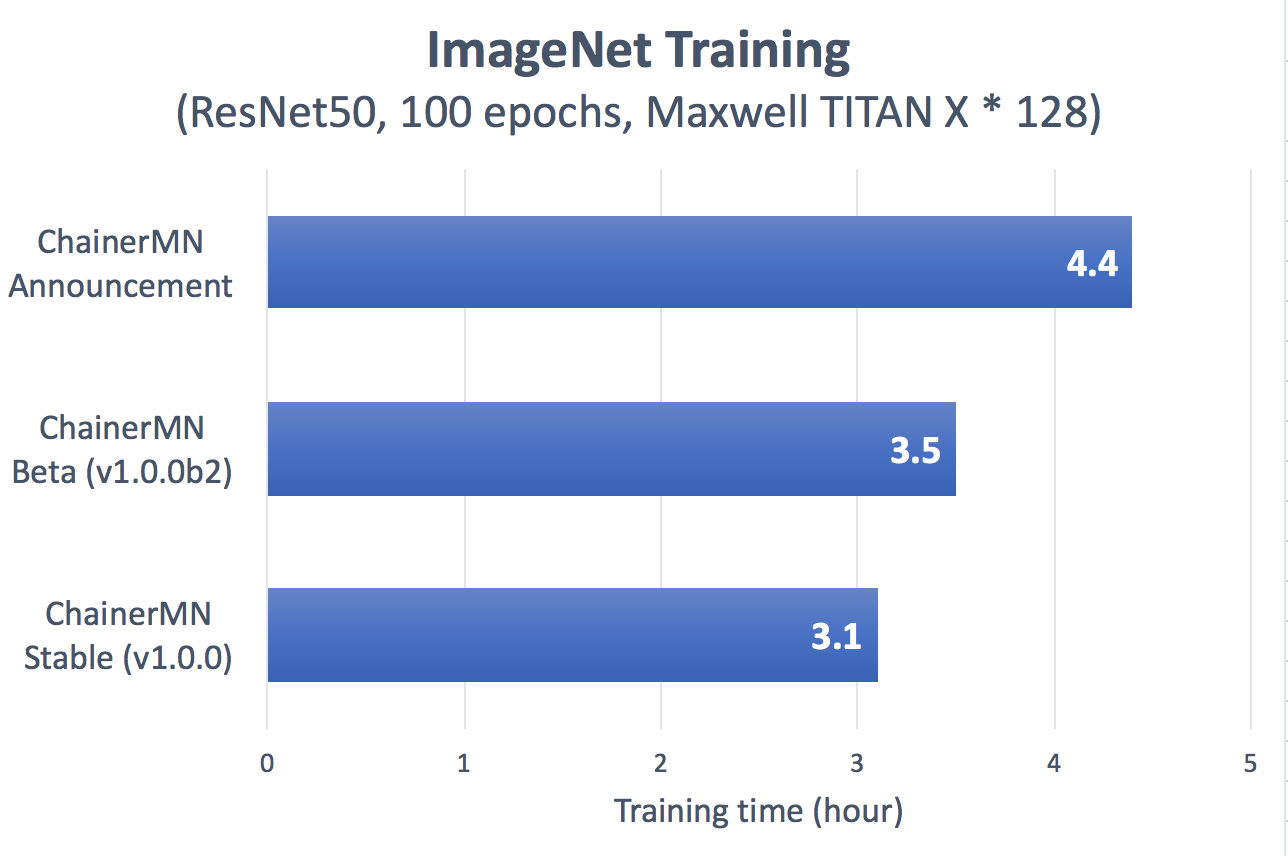
Preferred Networks officially released ChainerMN version 1.0.0, a multi-node distributed learning package, making it even faster with stablized data-parallel core functions
Contact us here.