Privacy Policy
Projects
News
Company
Careers
Chainer
Tag
Category
Year
Keyword
News Release
2020.05.12
Preferred Networks Deepens Collaboration with PyTorch Community
2019.12.05
Preferred Networks Migrates its Deep Learning Research Platform to PyTorch
2019.05.16
Preferred Networks releases version 6 of both the open source deep learning framework Chainer and the general-purpose matrix calculation library CuPy
2019.02.01
Nihon Keizai Shimbun Best Awards at the Nikkei Superior Products and Services Awards 2018
2018.12.03
Preferred Networks releases ChainerX, a C++ implementation of automatic differentiation of N-dimensional arrays, integrated into Chainer v6 (beta version) for higher computing performance
2018.10.25
Preferred Networks releases version 5 of both the open source deep learning framework, Chainer and the general-purpose array calculation library, CuPy.
2018.09.07
Preferred Networks wins second place in the Google AI Open Images – Object Detection Track, competed with 454 teams
Event
2018.05.17
Chainer awarded the Open Source Data Science Project Award Winner at ODSC East 2018
2018.04.17
Preferred Networks released open source deep learning framework Chainer v4 and general-purpose array calculation library CuPy v4.
2017.11.10
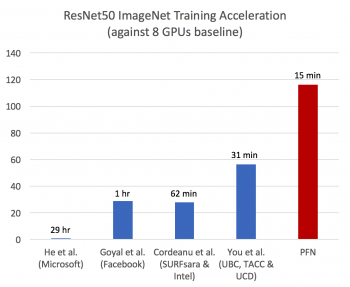
Preferred Networks achieved the world’s fastest training time in deep learning, completed training on ImageNet in 15 minutes,using the distributed learning package ChainerMN and a large-scale parallel computer
2017.10.17
Preferred Networks released open source deep learning framework Chainer v3 and NVIDIA GPU array calculation library CuPy v2
2017.09.20
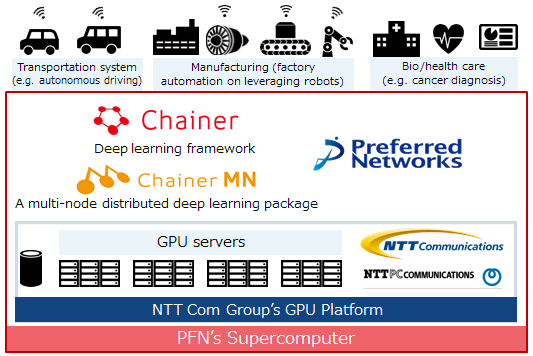
Preferred Networks Launches one of Japan’s Most Powerful Private Sector Supercomputers
Contact us here.