Privacy Policy
Projects
News
Company
Careers
2018
Category
Year
Keyword
News Release
2018.12.12
Preferred Networks develops a custom deep learning processor MN-Core for use in MN-3, a new large-scale cluster, in spring 2020
2018.12.03
Preferred Networks releases the beta version of Optuna, an automatic hyperparameter optimization framework for machine learning, as open-source software
Preferred Networks releases ChainerX, a C++ implementation of automatic differentiation of N-dimensional arrays, integrated into Chainer v6 (beta version) for higher computing performance
Internship
2018.12.01
Summer Internship 2019 for students from outside of Japan
2018.11.15
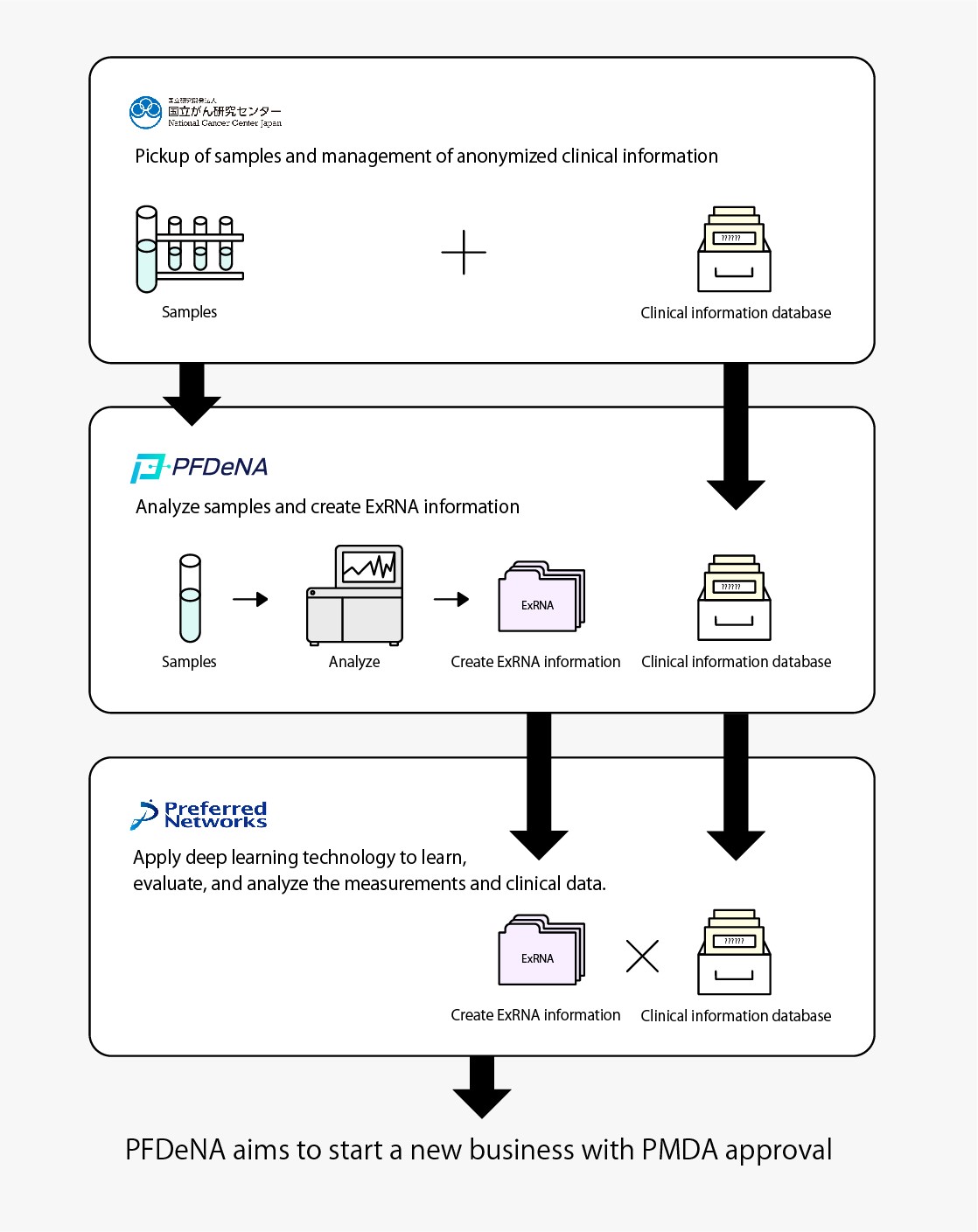
Mitsui and Preferred Networks to Establish Joint Venture to Provide Biomedical/Healthcare Solutions, Including Cancer Diagnostic Service, Based on Deep Learning Technology
2018.10.29
Preferred Networks and PFDeNA launch joint research project to develop a deep learning-based system to detect 14 types of cancers with a small amount of blood
2018.10.25
Preferred Networks releases version 5 of both the open source deep learning framework, Chainer and the general-purpose array calculation library, CuPy.
Event
2018.10.15
Preferred Networks unveils a personal robot system at CEATEC Japan 2018, exhibiting fully-autonomous tidying-up robots
Topic
Preferred Networks hired Professor Takeo Igarashi of The University of Tokyo as a Technical Advisor
2018.10.11
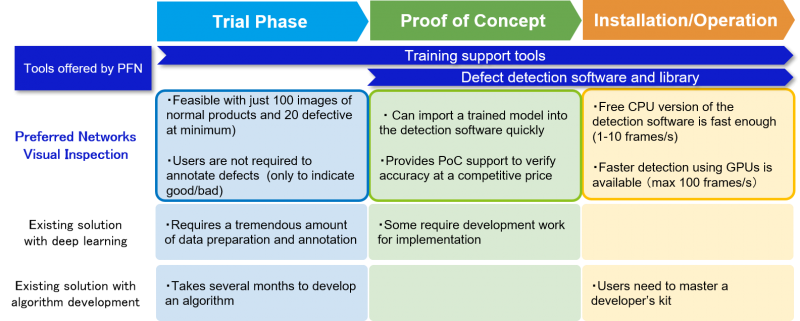
Preferred Networks releases deep learning-based, high-precision, visual inspection software
2018.09.07
Preferred Networks wins second place in the Google AI Open Images – Object Detection Track, competed with 454 teams
2018.08.03
Preferred Networks will exhibit at CEATEC JAPAN 2018 with CEO Toru Nishikawa scheduled to make a keynote speech titled “Robots for Everyone”
Contact us here.